Nota: Nos ficheiros exemplo.py vão inseridas algumas explicações acerca do código.
Publicado em 30 de Janeiro de 2015 pelas 15h50
Numa primeira fase procedeu-se à leitura da informação recolhida em genbank, diretamente da plataforma NCBI, utilizando apenas a sequência que corresponde ao intervalo de genes [lpg0001 a lpg0215], guardou-se essa sequência no ficheiro sequence.gb e leram-se as features do tipo CDS e o gene da sequência em questão.
O número total de features da sequência é diferente da soma do número de features do tipo CDS com o tipo gene, o que indica a existência de outros tipos de features, como Source.
Correndo o ficheiro geral.py, obtiveram-se várias informações sobre o ficheiro, como a sequência e qual o seu alfabeto, a sua identificação, os grupos taxonómicos associados, bem como alguns qualifiers importantes para a sua identificação cientifica(estão devidamente identificados no ficheiro python abaixo). Os qualifiers das features do tipo CDS não são os mesmos que os das features do tipo gene. Atenção que lpg0069 corresponde ao tRNA.
functionsizeprotein.py dá o tamanho de uma sequência; é utilizado para ver o tamamanho das proteínas do tipo CDS
De forma a validar as features CDS e Gene com a tabela fornecida pelo NCBI, procedeu-se da seguinte forma: a validação pode ser efectuada vendo se os GeneID's sequências de cada feature correspondem aos GeneID's dos genes [lpg0001 a lpg0215] na tabela fornecida pelo NCBI. Como anteriormente tinham sido criadas listas com cada qualifier de cada feature, utilizou-se a lista do GeneID (como sendo a parte prática) para proceder a essa comparação. Quanto à parte teórica, procurou-se obter o GeneID da tabela, e colocar numa lista.
Procedeu-se à comparação vendo se o GeneID correspondia a algum GeneID da lista teórica criada. Concluiu-se que o gene com GeneID:19831636 não se encontra na tabela de validação, pelo que não é validado.
A informação complementar que está associada à sequência em estudo pode ser obtida fazendo um programa que dá as anotações correspondentes (analisefeatseq.py), a informação referente às diferentes features pode ser obtida pelos dicionarios criados em busca dos vários qualifiers, tal como tradução da sequência e função em CDS ou localização nos dois tipos de features.(geral.py)
Nota-1: De forma a facilitar a procura e a validação, gastando menos tempo de processamento, a tabela em questão foi reduzida apenas para os genes em estudo
Nota-2: A existência do bloco try deve-se a inexistência de funções em algumas features.
Nota-3: Nos ficheiros exemplo.py vão inseridas algumas explicações acerca do código.
O número total de features da sequência é diferente da soma do número de features do tipo CDS com o tipo gene, o que indica a existência de outros tipos de features, como Source.
Correndo o ficheiro geral.py, obtiveram-se várias informações sobre o ficheiro, como a sequência e qual o seu alfabeto, a sua identificação, os grupos taxonómicos associados, bem como alguns qualifiers importantes para a sua identificação cientifica(estão devidamente identificados no ficheiro python abaixo). Os qualifiers das features do tipo CDS não são os mesmos que os das features do tipo gene. Atenção que lpg0069 corresponde ao tRNA.
functionsizeprotein.py dá o tamanho de uma sequência; é utilizado para ver o tamamanho das proteínas do tipo CDS
De forma a validar as features CDS e Gene com a tabela fornecida pelo NCBI, procedeu-se da seguinte forma: a validação pode ser efectuada vendo se os GeneID's sequências de cada feature correspondem aos GeneID's dos genes [lpg0001 a lpg0215] na tabela fornecida pelo NCBI. Como anteriormente tinham sido criadas listas com cada qualifier de cada feature, utilizou-se a lista do GeneID (como sendo a parte prática) para proceder a essa comparação. Quanto à parte teórica, procurou-se obter o GeneID da tabela, e colocar numa lista.
Procedeu-se à comparação vendo se o GeneID correspondia a algum GeneID da lista teórica criada. Concluiu-se que o gene com GeneID:19831636 não se encontra na tabela de validação, pelo que não é validado.
A informação complementar que está associada à sequência em estudo pode ser obtida fazendo um programa que dá as anotações correspondentes (analisefeatseq.py), a informação referente às diferentes features pode ser obtida pelos dicionarios criados em busca dos vários qualifiers, tal como tradução da sequência e função em CDS ou localização nos dois tipos de features.(geral.py)
Nota-1: De forma a facilitar a procura e a validação, gastando menos tempo de processamento, a tabela em questão foi reduzida apenas para os genes em estudo
Nota-2: A existência do bloco try deve-se a inexistência de funções em algumas features.
Nota-3: Nos ficheiros exemplo.py vão inseridas algumas explicações acerca do código.
|
| ||||
|
| ||||
O ficheiro pickone.py apresenta um algoritmo para a obtenção das informações de cada feature gene/cds, dando também o resultado do número de features de cada tipo, neste caso temos: 214 CDS e 215 Gene num total de 432 features.
| pickone.py |
Publicado em 30 de Janeiro de 2015 pelas 15:48
Análise de literatura:
De forma procurar alguma informação sobre a Legionella pneumophila subsp. pneumophila str. Philadelphia 1 fez-se uma busca literária com uma visão geral acerca do genoma desta bactéria, entre outras, info em Literatura, criando-se, também, um script que procura todos os artigos relacionados com a legionella Pneumophila na base de dados PubMed. Depois de procurar essa informação, guardou-se num ficheiro .txt , o título do artigo, o autor e a companhia que publicou o artigo (Source).
Para facilitar a visualização das funções dos genes fez-se o seguinte mapa (inspirado no do grupo 7), do ficheiro proteinfunction.py conclui-se a existência de 113 genes com funções desconhecidas e 101 genes com funções conhecidas num total de 214 genes e como alguns não tinham funções associadas, procedeu-se a uma análise desses genes recorrendo a bases de dados, como Uniprot,NCBi, etc. que se encontram no ficheiro func_genes.xls.
De forma procurar alguma informação sobre a Legionella pneumophila subsp. pneumophila str. Philadelphia 1 fez-se uma busca literária com uma visão geral acerca do genoma desta bactéria, entre outras, info em Literatura, criando-se, também, um script que procura todos os artigos relacionados com a legionella Pneumophila na base de dados PubMed. Depois de procurar essa informação, guardou-se num ficheiro .txt , o título do artigo, o autor e a companhia que publicou o artigo (Source).
Para facilitar a visualização das funções dos genes fez-se o seguinte mapa (inspirado no do grupo 7), do ficheiro proteinfunction.py conclui-se a existência de 113 genes com funções desconhecidas e 101 genes com funções conhecidas num total de 214 genes e como alguns não tinham funções associadas, procedeu-se a uma análise desses genes recorrendo a bases de dados, como Uniprot,NCBi, etc. que se encontram no ficheiro func_genes.xls.
|
| ||||||||
A bactéria em questão apresenta a sua classificação Científica dirigida da seguinte forma:
Estas informações foram obtidas pelo Script implementado no ficheiro.py. A imagem representa o output associado.
- Reino- Bactérias
- Filo- Proteobactérias
- Classe- GammaProteobacterias
- Ordem- Legionellales
- Famílias- Legionellaceae
- Género- Legionella
- Espécie- Legionella Pneumophila
- Subespécie- Legionella pneumophila subsp. pneumophila
Estas informações foram obtidas pelo Script implementado no ficheiro.py. A imagem representa o output associado.
| linhagem.py |

Publicado em 02 de Fevereiro de 2015 pelas 15h20
O Blast pode ser realizado para a análise de homologias. Para isso utilizou-se como query, a sequência de cada feature (neste caso, a sequência traduzida), sendo apenas válidas as features do tipo CDS. Criou-se um ficheiro com as informações dos alinhamentos e homologia para cada locus_tag selecionado.
| blast1.py |
Publicado em 02 de Fevereiro de 2015 pelas 23h45
Ferramentas de análise das propriedades da proteína
O script criado baseou-se na obtenção das propriedades das proteínas de interesse, tendo em conta a base de dados Uniprot. Desta base de dados fez-se o download do ficheiro txt (uniprot-proteome.txt) com todas as proteínas da nossa região de interesse. Depois procedeu-se à obtenção de todas as proteinas, reviewed e unreviewed com algumas informações sobre cada proteína (encontra-se compactado no ficheiro Proteinas_Reviewed.txt). De seguida procedeu-se a uma análise das 20 proteínas reviewed (uniprot_proteinas_reviewed.rar) das quais 2 são hypothetical proteins.
Já a base de dados PDB contém informação sobre a estrutura das proteínas.
Posto isto e excluindo todas as hypothetical proteins, desta base de dados foram obtidas 18 proteínas revistas cujas funções estão abaixo indicadas no ficheiro Excel.
O script criado baseou-se na obtenção das propriedades das proteínas de interesse, tendo em conta a base de dados Uniprot. Desta base de dados fez-se o download do ficheiro txt (uniprot-proteome.txt) com todas as proteínas da nossa região de interesse. Depois procedeu-se à obtenção de todas as proteinas, reviewed e unreviewed com algumas informações sobre cada proteína (encontra-se compactado no ficheiro Proteinas_Reviewed.txt). De seguida procedeu-se a uma análise das 20 proteínas reviewed (uniprot_proteinas_reviewed.rar) das quais 2 são hypothetical proteins.
Já a base de dados PDB contém informação sobre a estrutura das proteínas.
Posto isto e excluindo todas as hypothetical proteins, desta base de dados foram obtidas 18 proteínas revistas cujas funções estão abaixo indicadas no ficheiro Excel.
|
| ||||||||||
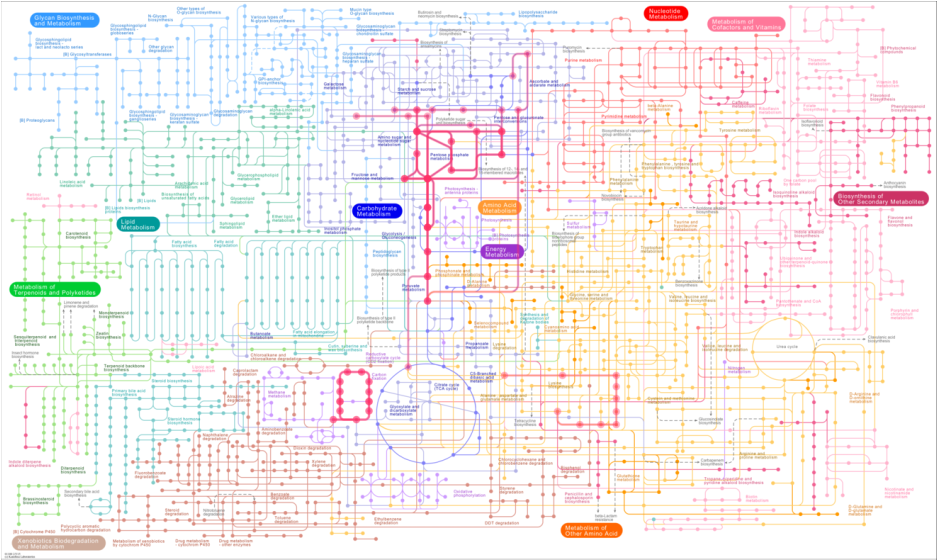
Procedeu-se a uma análise complementar das vias metabólicas, através da base de dados KEGG, sendo o resultado obtido um mapa metabólico representado na imagem seguinte. O ficheiro abaixo apresentado contém a compactação final de todas as informações obtidas para os genes da parte correspondente (ficheiro Excel).
| trabalhobio.xlsx |
Numa última fase foi feita uma análise acerca da virulência e resistência a antibiótico do genoma da Legionella pneumophila subsp. pneumophila str. Philadelphia 1. A análise global é apresentada no ficheiro Excel em baixo exibido, sendo dada especial importância aos 3 genes que se encontram a amarelo, correspondendo estes à porção de genoma analisada [lpg0001 a lpg0215].
| specialtygene_.xlsx |
